
招聘
反击OpenAI,谷歌放出最强悍大模型Gemini
OpenAI空前崛起之际,谷歌毅然打响了绝地反击战。
北京时间12月7日凌晨,谷歌CEO桑达尔.皮查伊和Deepmind CEO戴密斯·哈萨比斯在谷歌官网联名发文,官宣了最新多模态大模型Gemini 1.0(双子星)版本正式上线。这个上线时间早于外界猜测的明年1月,保密程度很高,仅有少数媒体提前猜出。
Gemini 1.0是谷歌筹备了一年之久的GPT4真正竞品,也是目前谷歌能拿出手的功能最为强悍、适配最为灵活的大模型,包括三种不同套件,分别是Gemini Ultra, Gemini Pro和Gemini Nano。其中Ultra的能力最强,复杂度最高,能够处理最为困难的多模态任务;Pro能力稍弱,是一个可扩展至多任务的模型;Nano则是一款可以在手机端侧运行的模型。这说明,Gemini的触达范围很广,可以下探至数据中心,也可以上行至移动设备端侧。
谷歌的Bard聊天机器人,此番也已经升级到了Gemini,可以说Gemini的初始版本已于今日开始在Bard中提供。从5月的I/O大会之后,谷歌就将自己此前最强的人工智能模型PaLm 2融入了Gemini的能力之中。
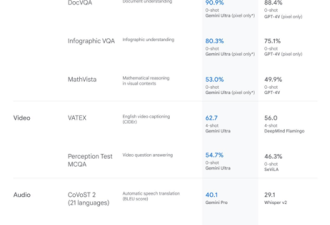
在一段公布的演示视频中,桑达尔.皮查伊展示了Gemini对视频、图像的非同凡响的识别能力。在视频中,Gemini极为自如地在图像、音频、视频各模态之间的转换,展现了惊人的解锁应用场景与产品形态的潜力。

仅从谷歌释出的演示视频结果看,市面上现有的全部多模态大模型与Gemini的性能表现都有代际差,包括Meta 5月开源的跨6个模态的AI模型ImageBind以及GPT-4。

今年4月开始,随着多模态技术不断升级,以及叠加模型调用成本等性能的优化,GPT4及国内外一众模型持续迭代,实现了跨模态性能的不断增强。一时间,多模态大模型呈百花齐放之势。但有国内头部大模型初创开发工程师对界面新闻记者表示,现今绝大部分多模态大模型都是在大语言模型LLM之上生长出多模态的应用,而并非从头开始训练的多模态的大模型,这是多模态大模型目前“不能言说的秘密”。

谷歌自己也提到,到目前为止,创建多模态模型的标准方法基本是针对不同模态训练单独的组件,然后将它们拼接以粗略模仿其中一些功能。这会导致这些模型有时擅长执行某些任务,例如描述图像,但难以处理更概念性和复杂的推理。
其通过60页的相关技术报告证明,Gemini是一个真正原生的多模态大模型,因为从最初的预训练数据开始,Gemini就在针对不同模态的模型进行训练,因此其功能在每个重大领域都达到了SOTA(State of the art,特指领先水平的大模型)。

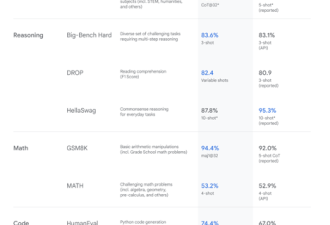
在权威MMMU基准测试中,Gemini Ultra获得了59.4%的SOTA分数。这项基准测试是经典的多模态测试,由跨不同领域的多模式任务组成,能够体现大模型的深度推理能力,而推理过程本身,需要花费的成本要远远高于模型训练。谷歌技术报告同时显示,谷歌是使用TPUv5e和TPUv4来训练Gemini,尤其是训练Gemini Ultra时,使用了跨多个数据中心的大量TPUv4。
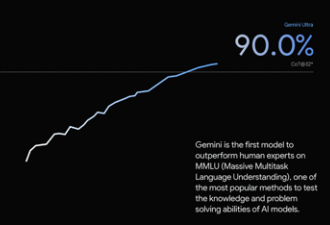
多模态能力之外,Gemini在专业知识储备和高级编码等领域都处在最前列。比如,Gemini Ultra在MMLU(大规模多任务语言理解数据集)中的得分率高达90.0%,这款MMLU数据集包含数学、物理、历史、法律、医学和伦理等57个科目,专门用于测试大模型的知识储备和解决问题能力。Gemini Ultra是第一个在MMLU上超越人类专家的大模型。
值得一提的是,谷歌此番并没有透露Ultra和Pro版本的具体参数规模,但根据量子位的分析,Gemini与谷歌此前的主力大模型PaLM-2相比,参数规模上要增大许多。此前,PaLM-2被曝参数规模为3400亿。
谷歌方面表示,Gemini将通过谷歌产品推向数十亿用户。从12月13日开始,开发者和企业客户可以通过Google AI Studio或Google Cloud Vertex AI中的Gemini API访问Gemini Pro。
今天凌晨,谷歌还同步发布了最新版本的计算芯片TPU v5p,相较上一代TPU v4性价比提升2.3倍,但这则消息完全被Gemini的光芒所掩盖。
生活服务
查看全部 1 条评论
查看全部 1 条评论





![[集市好物]2019 Nissan Sentra](https://storage.51yun.ca/auto-car-photos/7864b341-d836-4a14-bc25-4dad5499a71f.1080x810.jpg)








网友评论