
服务
OpenAI机器人炸裂登场!ChatGPT终于有身体了

以 GPT-4 为代表的大模型已经建造了大脑,下一步则是需要能承载这一大脑的机器人躯体。
昨天深夜,人形机器人明星公司 Figure AI 震撼发布了一段视频,展示了他们的机器人 Figure 01 在 OpenAI 强大模型的支持下,进行的一系列对话交互。

视频中的机器人展现出了灵活的操作反应,其与人类沟通的流畅度几乎可以与真人相媲美。
这距离 Figure AI 获得 OpenAI、微软、英伟达等公司投资,仅仅过去了不到半个月。也让我看到,OpenAI 最强的多模态大模型有了身体后会是什么样子。
Figure 01,最懂你的人形机器人?
得益于 OpenAI 多模态大模型的强大支持,Figure 01 现在可是个桌上物品识别的小能手。苹果、沥水架、水杯和盘子,对它来说都是小菜一碟!

饿了,想让它整口吃的,它能秒懂你的心思,麻溜地递上一个苹果。

而且,它甚至能在捡起你丢弃的垃圾,边还能跟你解释为啥刚才给了你苹果。在大模型的辅助下,Figure 01 可以理解桌面上唯一的食物——苹果。

在人类的一声令下,Figure 01 还能做家务,收拾餐具,这机器人,简直是家庭生活的最佳伙伴。
广大网友在看到这段令人惊艳的视频后,反应可谓是五花八门。
网友已经迫不及待地给 Figure 01 安排任务了,任务清单里怎么还混进了机器人前辈的电影。
竞争对手怕是要看在眼里,急在心里,准备暗地里摩拳擦掌,来一场技术大比拼?
更兴奋的网友表示,AGI 的曙光似乎就在眼前。

当然,总有些挑剔的声音,有的网友就吐槽说,这机器人说法怎么结结巴巴呢?
网友也没放过玩梗的机会。
Figure AI 掌门人 Brett Adock 也不甘寂寞,在 X 上跳出来做了一番精彩解读。
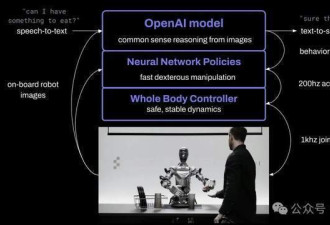
视频展示了端到端神经网络的应用(end-to-end neural networks)。在此过程中没有使用遥控器(teleop)。视频是以实际速度(1.0倍速)拍摄的,并且是连续不断的。
如您在视频中看到的,机器人的速度有了显著的提升,我们正在逐步达到与人类相似的速度。
无需遥控,自学成才
那么 Figure 01 是怎么做到的呢?
Figure AI 团队负责人 Corey Lynch 在 X 上解释了一番。
具体来说,视频中展示的所有行为都是通过学习获得的(非遥控操作),并且以实际速度(1.0 倍速)执行。
Figure AI 将机器人摄像头拍摄的图像和通过板载麦克风记录的语音转录文本输入到一个由 OpenAI 训练的多模态模型中,这个模型能够同时理解图像和文本信息。
该模型会处理整个对话的历史记录,包括以往的图像,以生成语言响应,并通过文本到语音的方式向人类回话。同一个模型还负责决定执行哪种已学习的闭环行为来响应给定的命令,它将特定的神经网络权重加载到 GPU 上,并执行相应的策略。
而将 Figure 01 连接到一个大型预训练的多模态模型,为其带来了许多有趣的新功能。
现在,Figure 01 + OpenAI 能够:
1 详述其周围环境。
2 在决策时运用常识推理。例如,“桌子上的餐具,像那个盘子和杯子,很可能接下来会被放到烘干架上”。
3 将含糊的高级指令,如“我饿了”,转化为符合情境的适当行为,比如“递给那个人一个苹果’。
4 用简单的英语解释为什么它执行了某个特定的动作。例如,“这是我能够从桌子上提供的唯一可食用物品”。
当谈到 Figure 01 通过学习掌握的精细双手操作技能时,其实这背后也蕴含着一系列复杂而精妙的原理。
所有行为都由神经网络的视觉-运动转换器策略驱动,这种策略能直接将图像像素映射到动作。这些网络以每秒 10 帧的速率接收机器人内置图像,并生成每秒 200 次的 24 自由度动作(包括腕部姿势和手指关节角度)。
这些动作作为高速“设定点”,供更高速率的全身控制器跟踪,确保动作的精确执行。
这种设计实现了关注点的有效分离:
1 互联网预训练模型对图像和文本进行常识推理,以生成一个高级计划。
2 学习到的视觉-运动策略执行这个计划,完成那些难以手动指定的快速、反应性行为,例如在任何位置操纵一个可变形的袋子。
3 同时,全身控制器负责确保动作的安全性和稳定性,例如,保持机器人的平衡。
对于 Figure 01 取得的巨大进步,Corey Lynch 感慨道:
就在几年前,我还认为与一个能自主规划和执行学习行为的人形机器人进行完整对话,将是未来数十年后的事情。显然,许多事情已经发生了巨大变化。
这会是人形机器人的 GPT 时刻吗
不得不说,Figure 01 的发展速度简直像是踩了油门,一路狂飙。
今年 1 月,Figure 01 就掌握了制作咖啡的技能,这一成就得益于端到端神经网络的引入,使得机器人能够自主学习和纠正错误,仅需10小时的训练。

一个月后,Figure 01 已经学会了搬运箱子并运送至传送带的新技能,尽管其速度仅为人类的 16.7%。
在这个过程,Figure AI 商业化的步伐也未曾停歇,与宝马制造公司签订了商业协议,将 AI 和机器人技术融入汽车生产线,并落户于宝马的工厂。
紧接着,就在两周前,Figure 宣布完成了 6.75 亿美元的 B 轮融资,公司估值飙升至 26 亿美元。

投资方几乎涵盖了硅谷的半壁江山——Microsoft、OpenAI 创业基金、英伟达、Jeff Bezos、Parkway Venture Capital、Intel Capital 和 Align Ventures 等。
当时,OpenAI 与 Figure 还宣布将共同开发下一代人形机器人 AI 模型,OpenAI 的多模态模型将扩展到机器人感知、推理和交互环节。
如今,从 Figure 01 身上,我们仿佛能窥见未来生活的草稿。
事实上,在大模型之前,机器人属于专用设备,如今有了大模型的通用能力,通用机器人开始曙光乍现,现在的我们不止需要 ChatGPT,还需要 WorkGPT。

这些进化间接印证了一条清晰可见的道路:当 AI 大模型生根发芽之后,总归是要走进现实世界,而具身智能则是最佳的路径。
一直活跃在 AI 前线的英伟达创始人黄仁勋曾洞察道:“具身智能将引领下一波人工智能浪潮。”
将 OpenAI 大模型融入 Figure 01 也是有意的战略布局。
成熟的 AI 大模型充当人工大脑,模拟了人脑复杂的神经网络,实现了语言理解、视觉识别、情景推理等认知功能,解决了机器人更高层次的认知和决策问题。
与此同时,各种传感器、执行器、计算单元被集成到机器人躯体中,实现了对环境的感知和交互。比如视觉系统可以捕捉图像和视频,触觉传感器可以感受物体的形状和质地等。

Figure AI 创始人 Brett Adcock 此前在接受采访时表示,未来 1-2 年,Figure AI 将专注于开发具有里程碑意义的产品,期望在未来一两年内向公众展示人形机器人的研发成果,涵盖 AI 系统、低级控制等,最终呈现能在日常生活中大展身手的机器人。
他还透露,在成本方面,一个人形机器人约有1000个零件,重约150磅(68公斤),而电动汽车可能有约1万个零件,重达4000-5000磅(1800-2250公斤)。因此,长期来看,人形机器人的成本有望低于廉价电动汽车,这取决于执行器、电机组件、传感器的成本及计算成本。
机器人专家 Eric Jang 曾提出他的洞见:“尽管许多 AI 研究者认为通用机器人的普及还需数十年,但别忘了,ChatGPT 的诞生仿几乎就在一夜之间。”
一年前的今天,OpenAI 震撼发布了 GPT-4,向世界证明了大模型的强大威力。
一年后的今天,我们没等来 GPT-5,但也迎来 Figure 01,而这会是人形机器人的 GPT-4 时刻吗?
生活服务
查看全部 1 条评论
查看全部 1 条评论



![[二手好物]全皮沙发 一大 一小](https://storage.51yun.ca/market-product-photos/fc413f9c-e5c3-40f9-844c-a30aebc8ce5f.1080x810.jpg)












网友评论