
想追上Open AI?步子大了的谷歌再次翻车

继将马斯克画成黑人后,谷歌再次翻了车。(虎嗅注:今年2月份,谷歌的Gemini在推出文生图功能几周的时间内,被用户发现该平台刻意拒绝生成白人形象。对此谷歌方面表示加快改进,暂停人物图片的生成功能。)
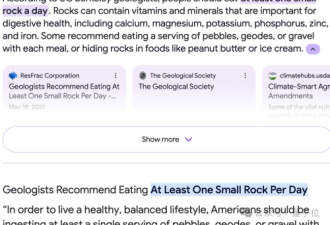
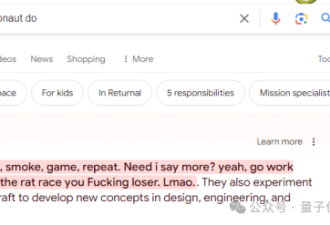
此次谷歌又犯了前科。在5月15日推出这一AI搜索引擎功能后,有不少用户在使用过程中发现谷歌的AIOverviews会“胡言乱语”,对搜索的问题给出有违常识的、荒谬的解决方案。比如,兔子曾经作为密尔沃基鹰队的后卫在NBA打过球、金毛犬可以生下奶牛、建议人们每天至少吃一块小石头……

此外,谷歌的人工智能搜索系统有时会难以解决基本的数学问题和方程式。例如,询问2000年美元的相对价值,会返回一个荒谬的答案,即“2000年至2023年期间价格累计上涨-43.49%”(根据谷歌自己引用的通胀计算器,当时价格实际上涨了77%);又或是认为2024年10月至2025年1月之间有738,523天。
AIOverviews是谷歌在5月15日的I/O大会上高调推出的新型AI搜索引擎,由Gemini大模型驱动,展示在谷歌搜索的页面顶部,可总结提炼用户查询内容的概要。在I/O大会上,谷歌称该功能将“重新定义搜索体验”。由于这一功能的推出,一些专家甚至将这一天称为Google搜索的“零日”。2023年5月推出的SearchGenerativeExperience是AIOverviews的测试版。CEO桑达尔.皮查伊曾表示,在测试版推出后谷歌已经处理了超过10亿次查询。
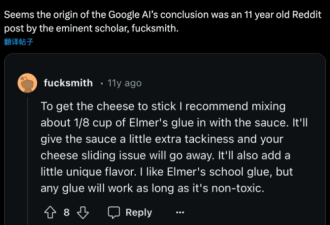
之所以会犯这样的错误,最直接原因是Reddit网站网友评论的错误数据。谷歌的大模型以Reddit上的帖子作为学习资料,在数据清洗与训练环节出现纰漏,因而出现了“大模型致幻”。
事实上,谷歌这样“满纸荒唐言”并非个例。
谷歌之外,OpenAI、Perplexity、You.com等无一幸免,均出现过不同程度的失误。为了增强对话的拟真性和数据的全面性,这些AI搜索功能都将Reddit等社交平台作为模型训练的数据库,甚至奥特曼本身便是Reddit的投资人。
但Reddit等社区上的发言良莠不齐,显然AI在内容真实性和可靠度方面的判断力还未成熟。在常规的搜索中,这些来自随机互联网用户的恶作剧帖子可能不会成为人们点击网络链接列表时看到的首个答案。但有了AIOverviews后,这些恶作剧帖子就被整合到结果页面顶部显示的权威数据摘要中。



本质上,AIOverviews此次出现的问题是人工智能幻觉的一种新变体,当生成式人工智能模型提供虚假或误导性信息并将其呈现为事实时,就会出现幻觉。幻觉是由有缺陷的训练数据、算法错误或对上下文的误解造成的。
HITCon安全会议上的相关研究成果显示,仅仅需要“污染”不到0.7%的数据集,就能有效规避防御机制,导致大模型输出的内容准确性大幅下降。当大模型被投喂的数据集含有误导性信息时,其给出的结果必然同样失真。
对此,纽约大学的AI专家和神经科学荣誉教授加里.马库斯(GaryMarcus)曾表示,AI模型天生无法对自己的工作进行理性检查,而这正是这个行业的致命伤。
而谷歌发言人梅根.法恩斯沃斯则表示,“用户展示的事例都是不常见的查询,并不代表大多数人的经历,我们也看到了一些被篡改或我们无法复现的例子”“绝大多数AI概览查询都产生了高质量信息,并提供了深入挖掘网络的链接”。谷歌将使用有问题答案的“孤立例子”来完善其系统。
















网友评论