

华科AI模型预测新冠生存率准确率90%
当地时间3月17日,医药学预印本平台medRxiv发布了一项题为“A machine learning-based model for survival prediction in patients with severe COVID-19 infection”(未经同行审议)的研究成果。这项由29名科学家共同进行的研究利用了最新的可解释机器学习算法,对预测COVID-19(新冠肺炎)患者存活率的生物标志物进行了揭示,并有望加强对新冠高危患者的早期干预,降低死亡率。
研究团队来自华中科技大学同济医学院附属同济医院、华中科技大学人工智能与自动化学院、剑桥大学植物科学学院等。文章的通讯作者为华中科技大学人工智能与自动化学院教授袁烨、同济医院麻醉科徐卉以及急诊(重症)医学科科主任李树生。
研究人员对武汉同济医院收治的404例COVID-19感染患者进行血液样本数据收集并进行回顾性分析。通过机器学习工具,研究团队最终选择了3种生物标志物来预测个体患者的生存率,准确性超过90%:LDH(乳酸脱氢酶)、淋巴细胞和hs-CRP(超敏C-反应蛋白)。
特别是,仅LDH水平较高这一项指标就能够用于区分绝大多数需要立即就医的病例。研究者们表示,这一发现与当前医学知识一致,即高LDH水平与各种疾病(包括肺部疾病,如肺炎)中发生的组织分解有关。
在当前阶段,对疾病的严重程度进行快速、准确和早期的临床评估至关重要。然而目前,尚无确定的生物标志物作为标准,来区分需要立即就医的患者。
此研究中,作者们运用最先进的机器学习框架,表明上述三种生物标记物可以准确预测疾病的严重程度,因此将大大减轻临床参数监测的压力和其他相关的医疗负担。
研究人员开发了基于XGBoost机器学习的预后模型,该模型使用患者最新一个血样样本能够以90%以上的准确度预测COVID-19重症患者是否存活;使用其他血液样本则能达到90%的预测准确度。
该研究提出了一个简单且可操作的公式,能够对新冠高危患者进行快速检测、早期干预并有可能降低他们的死亡率。
研究样本与模型训练
研究人员进行了分类任务,将一般(general)、严重(severe)、危重(critical)患者的基本信息、症状、血液样本、实验室检查结果(包括肝功能、肾脏功能、凝血功能、电解质、发炎因子)输入,并将它们与检测时期结束时的临床后果(存活或死亡)相对应。
研究样本是同济医院2020年1月10日至2月20日期间收集的404位患者的医疗信息。这404位患者中,有213位康复,其余191位死亡,作者们表示,高死亡率与同济医院作为定点医院,收治了最严重的病例有关。研究人员使用标准病例报告表收集病历,其中包括流行病学、人口统计学、临床、药物、护理和死亡率等信息。
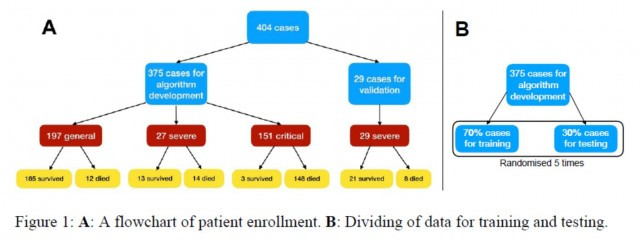
研究人员用375例患者信息进行算法开发(algorithm development),用29例作验证集(validation)
研究人员将患者的数据分为训练集(training)、测试集(test)和其他验证集(additional validation)。培训和测试集共计包含375名患者,而验证集包括29名患者。训练和测试集的样本数按照7:3的比例设置,再进行5次交叉验证。
验证集中的患者均为严重患者,因为就临床结果而言,他们是最不可预测的。从临床症状来看,发烧是最常见的初始症状(49.9%),其次是咳嗽(13.9%),疲劳(3.7%)和呼吸困难(2.1%)。375名患者的年龄分布为58.83±16.46岁,男性占58.7%。患者中有37.9%是武汉居民,家族聚集性病例占6.4%,医疗工作者占1.9%。

样本患者的年龄、性别、流行病史等特点
尽管大多数患者在整个住院期间都采集了多个血液样本,但模型训练和测试仅使用了患者最近一次的血样记录作为输入,以得到评估疾病严重程度的关键生物标志物,区分需要立即医疗救助的患者以及准确匹配每个标签的相应功能。

患者3种生物标志物的中位数值,以及25和75的百分位值
与死亡风险最相关的临床特征
研究人员使用了一种名为XGBoost的分类器作为预测器模型,XGBoost是一种高性能的机器学习算法,由于其基于树型(tree-based)方法的递归决策系统,其具有巨大的可解释性。模型的输出对应着患者的生存情况,研究人员将幸存的患者归为0类,死亡的患者归为1类。
研究人员没有采用黑匣子建模(black-box modelling)策略的原因在于,其内部模型机制通常很难解释。在XGBoost中,每个单个功能的重要性取决于其在树中每个决策步骤中的累积使用量。这样就可以在其中得到一个度量标准,来表征每个特征的相对重要性,这对于评估模型结果中最具区别性的特征特别有价值,尤其是当研究与临床上的医疗参数有关时。
为了评估发生死亡风险的标记,研究人员通过特征选择过程评估了每个患者参数对算法决策的贡献。XGBoost根据功能的重要性对功能进行了排名,该算法选择了三个排名最靠前的临床特征:LDH、淋巴细胞和hs-CRP,因此,它们被设置为关键特征。
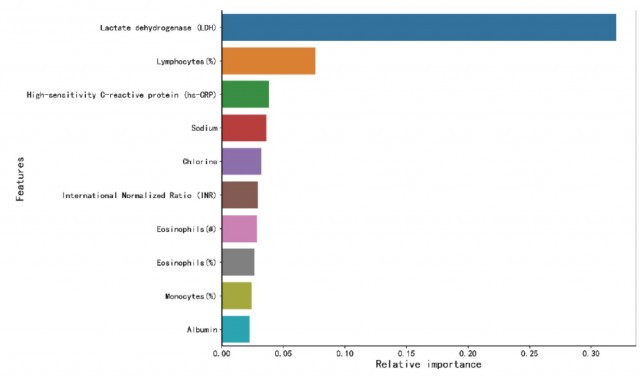
根据其在多树XGBoost算法中的重要性,研究人员对十大关键临床特征进行了排名,LDH,淋巴细胞和hs-CRP排名前三
结果表明,该模型能够准确预测患者的结局,而无需考虑入院时的最初诊断。
此外,附加验证集的性能类似于训练和测试集的性能,这表明该模型捕获了有关患者生存的关键生物标志物。同时,算法结果进一步强调了LDH作为患者生存率的关键生物标志物的重要性。
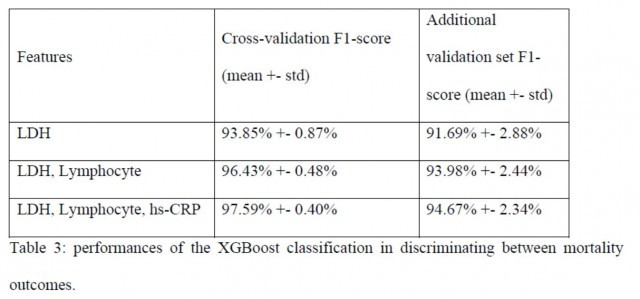
三大关键特征的训练/测试拆分和附加验证集的模型性能,F1分数(F1-score)是算法精确率和召回率的调和平均数,最大为1,最小为0
根据关于LDH,淋巴细胞和hs-CRP重要性的发现,研究人员进一步构建了简化的且可在临床上应用的决策模型,即单个决策树(single decision tree)。由于共有24例患者的三种主要生物标志物中至少有一种测量值不完整,研究人员利用剩下351例患者鉴定了单树XGBoost模型。
简单来说,就是研究人员选择了模型中性能最佳的树,使用三个关键特征及其阈值,可以预测病人死亡或是存活。
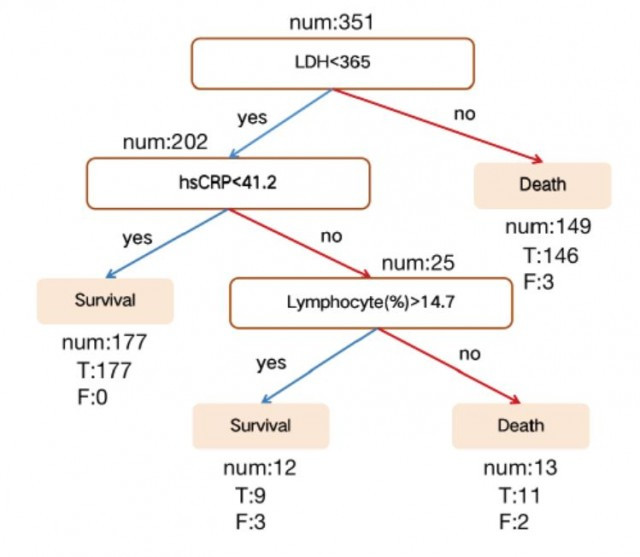
根据测试数据集选择的性能最佳的树及其准确性
这一模型显示了100%的死亡预测精度和90%的生存预测精度。总体而言,无论是多树XGBoost还是单树XGBoost模型,模型对于生存和死亡预测的准确性、宏观和加权平均数的得分始终超过0.90。
最后,大多数患者在住院期间都接受了多次血液采样。研究人员又通过上千份额外的血液测试结果对模型进行了验证,发现预测准确度达到了90%。此外相关结果进一步表明该模型可以应用于任何血液样本,无论患者有怎样的临床结果。
提早识别高危患者,快速确定优先级
研究者们表示,这项研究的意义是双重的。首先,一般的相关研究只会“提供高风险因素的范围”,而这一模型则提供了一种简单直观的临床测试,进而可以准确快速地量化死亡风险。
如果医生能够提早知道,对于某些患者来说某些疗法会导致治疗效果不理想,那么医生就能抢在病症变得更严重之前采用不同的方法。应用这一模型的目标是在不可逆性病变发生之前识别高危患者。
其次,任何一家医院都可以轻松收集病人的LDH(乳酸脱氢酶)、淋巴细胞和hs-CRP(超敏C-反应蛋白)这三个关键指标信息。在拥挤的医院中医疗资源短缺的情况下,这种简单的模型可以帮助快速确定患者的优先级。
患者LDH水平的增加能够反映组织或细胞的破坏,被认为是组织或细胞损伤的常见征兆。血清LDH已被确定为特发性肺纤维化(IPF)严重程度的重要生物标志物。
在患有严重肺间质疾病的患者中,LDH的增加是显著的,并且这是患者肺损伤最重要的预后指标之一。因此对于重症COVID-19患者而言,LDH水平的升高表明肺损伤的严重程度增加。
研究团队指出,较高的血清hs-CRP值也可用于预测严重COVID-19患者的死亡风险。hs-CRP的增加是ARDS(急性呼吸窘迫综合征)患者预后不良的重要标志,反映了炎症的持续状态。
值得注意的是,这种持续性炎症反应的结果可以从COVID-19死者的尸检中看到,即肺部出现大量灰白色病变,在组织切片中,还可见肺泡溢出大量黏性分泌物。
最后,研究结果还表明淋巴细胞可能充当潜在的治疗靶标,这一假说得到了临床研究结果的支持。此外,此前包括北京中日友好医院呼吸科主任曹彬团队在内的研究者们已经证明,淋巴细胞减少症是COVID-19患者的常见特征,可能是与疾病严重程度和死亡率相关的关键因素。
与SARS和MERS患者的肺泡穿透和抗原呈递细胞(APC)受损途径一样,新冠肺炎患者损伤的肺泡上皮细胞可以诱导淋巴细胞浸润,导致持续性淋巴细胞减少。
此前的一项患者活检研究表明,外周血CD4和CD8 T细胞的数量大大减少,而它们的状态被过度激活。此外,也有研究表示淋巴细胞减少症主要与CD4和CD8 T细胞的减少有关。因此,淋巴细胞可能在COVID-19中发挥着明显的作用,这值得进一步研究。
作者们表示,这项研究同样存在一定的局限性。首先,由于这一机器学习方法是纯粹由数据驱动的,因此,如果从不同的数据集开始研究,则模型可能会有所不同。
此外,尽管作者们掌握了80多项临床测量结果,但为了避免过拟合(overfitting),团队采用的建模原理是在最少临床测量结果数量和良好预测能力之间进行权衡,因此可能存在临床测量结果不够丰富的问题。
最后,这项研究在模型的可解释性和更高的准确性之间进行平衡。尽管临床环境倾向于使用可解释的模型,但如果采用黑匣子模型,则准确性可能更高,但同时决策风险更高。
从技术角度来看,作者们认为这项工作有助于使用机器学习方法为正在全球大规模暴发的COVID 19病例进行预测和诊断。
数据标本还太少,预测会存在一定误差的
回复


![[集市好物]26寸自行车](https://storage.51yun.ca/market-product-photos/72862071-74f7-47e5-8209-2c5c7eb73f0c.1080x1440.jpg)










网友评论